 用户登陆
用户登陆 站点日历
站点日历 日志搜索
日志搜索 站点统计
站点统计 最新评论
最新评论 友情链接
友情链接
 其他信息
其他信息





不过我们要区分蜘蛛的真伪,同时了解各种蜘蛛,屏蔽一些对网站无用的蜘蛛,避免养“蛛”为患。
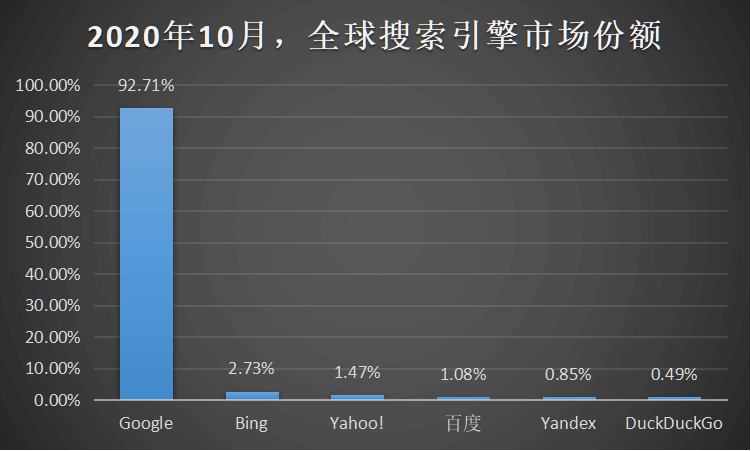
搜索引擎占有率

- Googlebot
Googlebot 是谷歌的搜索引擎蜘蛛。2021年8月,Google全球市场份额为92.05%,排名第一(即最大)因此不建议屏蔽 Googlebot。
- bingbot
bingbot 必应虫是微软的搜索引擎。截至2021年8月Bing 全球占有率为第2名,市场份额为2.45%。
必应集成了多个独特功能,包括每日首页美图,与 Windows 操作系统深度融合的超级搜索功能,以及崭新的搜索结果导航模式等。用户在内置于 Windows 操作系统的搜索栏,或 Edge 默认搜索引擎均可直达必应的网页、图片、视频、词典、翻译、资讯、地图等全球信息搜索服务。
随着 Edge 浏览器的流行、windows 超大的市场占有率,必应搜索引擎在国内份额将进一步提升。
必应 SEO:网站如何在必应中显示更丰富的形式
- Baiduspider
Baiduspider 是百度搜索引擎的蜘蛛呦!
识别百度蜘蛛(Baiduspider)的简单步骤
百度应用 UA:
Mozilla/5.0 (iPhone;CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko)Version/9.0 Mobile/13B143 Safari/601.1 (compatible; Baiduspider-render/2.0;Smartapp; +http://www.baidu.com/search/spider.html)
Baiduspider 详细介绍
图片搜索:Baiduspider-image
视频搜索:Baiduspider-video
新闻搜索:Baiduspider-news
百度搜藏:Baiduspider-favo
百度联盟:Baiduspider-cpro
商务搜索:Baiduspider-ads
网页以及其他搜索:Baiduspider
- Bytespider
Bytespider 这个爬虫是字节跳动旗下头条搜索的爬虫,其爬虫 UA 为:
#PC端
Mozilla/5.0 (compatible; Bytespider; https://zhanzhang toutiao com/)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.0.0 Safari/537.36
#Android端
Mozilla/5.0 (Linux; Android 5.0) AppleWebKit/537.36 (KHTML, like Gecko)
Mobile Safari/537.36 (compatible; Bytespider; https://zhanzhang toutiao com/)
#
iOS端
Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.36 (KHTML, like Gecko)
Version/7.0 Mobile Safari/537.36 (compatible; Bytespider; https://zhanzhang toutiao com/)
屏蔽头条搜索爬虫
如果不想头条搜索爬取自己的网站,可采用以下两种方法屏蔽头条搜索的爬虫:
#IP屏蔽
头条搜索的ip字段总共涉及10个ip,具体字段如下:
110.249.201.0/24
110.249.202.0/24
111.225.148.0/24
111.225.149.0/24
220.243.135.0/24
220.243.136.0/24
220.243.188.0/24
220.243.189.0/24
60.8.123.0/24
60.8.151.0/24
# robots.txt 屏蔽
Bytespider 遵守robots规则,可采用以下方法屏蔽:
User-agent: Bytespider
Disallow: /
- 头条搜索优化
头条搜索的站点配图一般是使用 og:image 标签(Open Graph Protocol Meta)来识别的,因此想要网页旁边出现漂亮合理的配图可在网页 <head></head> 中添加 Open Graph Protocol Meta 标签。

- Yisouspider
Yisouspider是神马搜索的蜘蛛。
- YandexBot
俄罗斯搜索巨头Yandex的蜘蛛,
- 360Spider
360搜索蜘蛛
- PetalBot
PetalBot 是华为自研搜索引擎的爬虫,叫做花瓣蜘蛛,将来或许也会在国内再杀出一个搜索引擎。现华为花瓣搜索引擎仅对欧洲用户开放。
PetalBot 符合 Internet 机器人协议。您可以使用 robots.txt 文件完全阻止 PetalBot 访问您的网站,或阻止 PetalBot 访问您网站上的某些文件。
为了获得对目标资源更好的检索结果,PetalBot 需要保持一定程度的网站爬网。我们力求不给网站带来不合理的负担,我们将根据服务器容量,网站质量和网站更新等综合因素进行调整。如果 PetalBot 的访问有任何不合理的行为,请将您的疑虑发送至 search@aspiegel.com。
- Sogou web spider
搜狗搜索引擎的蜘蛛。
- AhrefsBot
AhrefsBot 是国外网站的一个蜘蛛程序,那么 Ahrefs 是什么网站呢,这个是国外一个网络营销类的网站,有点类似于国内的5118、站长网之类,在 SEO 界比较有名的。AhrefsBot数据库里面有超过12万亿条链接,每天它就在不断的执行和监控Ahrefs的在线营销活动,每24小时就要访问超过60亿个网页,每15-30分钟就要更新一次索引。
根据一项调查显示,AhrefsBot是仅次于谷歌蜘蛛(Googlebot)的世界第二大活跃蜘蛛爬虫程序。
AhrefsBot 会增加你服务器的负担外,并不会对你的网站造成什么影响,它既不会触发网站上的广告,也不会在统计中增加流量。建议屏蔽 AhrefsBot
- SemrushBot
SemrushBot 是 SEMrush 的蜘蛛爬虫。
SEMrush是一家老牌的提供搜索引擎优化数据的公司,是一个强大的、全面的在线营销竞争情报平台,其中包括 SEO、PPC、社交媒体和视频广告研究。
建议网站屏蔽掉它的爬行,首先因为这个蜘蛛爬行并不会给网站带来流量,只会占用服务器资源,其次是这是已经数据分析公司的爬虫,它爬的数据会成为你竞争对手的分析利器。
如何屏蔽SemrushBot呢?
robots.txt 文件中添加以下代码即可:
User-agent: SemrushBot
Disallow: /
User-agent: SemrushBot-SA
Disallow: /
- BLEXBot
Blexbot是WebMeUp的蜘蛛爬虫,Blexbot每天可以抓取上百亿个页面来收集反向链接数据,并将该数据提供给其链接索引(在SEO SpyGlass中使用的链接索引)。
WebMeUp是美国的一家外链反向链接查询工具网站,他一般的形式是
Mozilla / 5.0(兼容; BLEXBot / 1.0; + http://webmeup-crawler.com/)
- AdsBot
Adsbot是谷歌 Google AdWords 的蜘蛛,也就是广告联盟的。
- MJ12bot
MJ12bot 是英国的一家老牌的搜索引擎营销网站 Majestic 的爬虫,他有专门的中文站,对外链查询等很多 SEO 数据查询提供数据支撑,做过外链的都知道,获取外链资源是一项基本能力,这个网站可以查询网站的外链资源数,不过很多公司看到日志里有这个 MJ12bot 蜘蛛,一般是选择直接屏蔽掉(MJ12bot 是 Majestic-12 分布式搜索引擎的爬虫)
官方给了一个修改 robots 的方法,就是在 robots.txt 文件中加入:
User-agent:MJ12bot
Disallow:/
- DotBot
DotBot是Moz的网络爬虫程序,Moz旗下链接分析网站opensiteexplorer专门用来分析网站SEO外链数据,BotBot蜘蛛爬虫就是为Moz服务,在互联网上抓取大量的网页进行各种数据分析。
如果我们不希望Dotbot抓取自己的网站,可以使用robots.txt进行屏蔽。DotBot遵robots.txt协议。
DotBot蜘蛛爬虫原型
Moz蜘蛛爬虫UA:”Mozilla/5.0 (compatible; DotBot/1.1; http://www.opensiteexplorer.org/dotbot, help@moz.com)”
网站如何禁止DotBot抓取
在我们的网站根目录中的robots.txt文件中写上如下代码:
User-Agent: DotBot
Disallow: /
- Applebot
Applebot 是 Apple 推出的网络爬虫工具。“Siri 建议”和“聚焦建议”等产品均使用 Applebot。这个工具遵循惯用的 robots.txt 规则和 robots 元标签,并且源自 17.0.0.0 网络块。
用户代理字符串包含“Applebot”和其他代理信息。示例如下:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/600.2.5 (KHTML, like Gecko) Version/8.0.2 Safari/600.2.5 (Applebot/0.1)
- CCbot
CCbot,全称为Common Crawl Bot,是一个非营利性基金会致力于提供可以被所有人访问和分析的Web爬网数据的开放存储库。
可以通告robts.txt屏蔽:
User-Agent: CCbot
Disallow: /
- DuckDuckGoBot
DuckDuckGoBot 是著名元搜索引擎 DuckDuckGo 的爬虫,另外还有 DuckDuckGo Favicons Bot 是用来获取网站 Favicon.ico 图标的蜘蛛。
DuckDuckGo 是美国的一个互联网搜寻引擎,其总部位于美国宾州Valley Forge市。DuckDuckGo强调在传统搜寻引擎的基础上引入各大Web 2.0站点的内容。其办站哲学主张维护使用者的隐私权,并承诺不监控、不记录使用者的搜寻内容。DuckDuckGo-Favicons-Bot
一般默认的形式是
Mozilla/5.0 (compatible; DuckDuckGo-Favicons-Bot/1.0; +http://duckduckgo.com)” – 0.047 0.047
- yacybot
yacy 搜索引擎蜘蛛。
- DataForSeoBot
DataForSEO 网站的蜘蛛。由于访问速率太大,建议小型网站进行屏蔽。
robots.txt 怎么写
#我们建议这样写:
User-agent: *
Allow: /
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: DataForSeoBot
Disallow: /
User-agent: *
Allow: /
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
User-agent: MJ12bot
Disallow: /
User-agent: DataForSeoBot
Disallow: /
 如果文章对您有帮助,给个赞赏吧!
如果文章对您有帮助,给个赞赏吧!

